This article is more than 1 year old
Reg readers love Private Cloud (true)
Playing the SLA long game
When IT is your day job it is easy to lose sight of why you are doing it. Alright, it’s to pay the bills, fund your next holiday, buy nice stuff and so on.
But from the point of view of whoever is paying your salary, the point is to enable and add value to the business. You and your colleagues in the IT department are there to provide a service.
Four fundamentals
How good that service is can be measured in all kinds of ways, but apart from providing appropriate systems and capability, it largely boils down to a few key functions:
- Maintaining system performance (response times, throughput and so on)
- Minimising downtime and ensuring full recovery after a failure
- Responding quickly to new business requirements and change requests
- Responding quickly to unexpected problems
Oh yes, and you will probably also be judged on how efficiently you operate.
So how well are IT departments performing? The results of a recent Reg reader survey of 570 respondents threw up a broad spectrum of performance levels. Some are doing a lot better than others (figure 1).
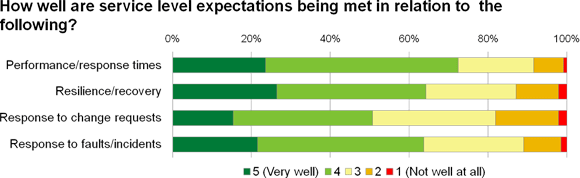
Figure 1
What we are looking at here is probably a best-case representation of performance across the IT community.
The survey this comes from was mostly about private cloud, which as a fairly new type of advanced solution will have attracted a disproportionately high number of respondents from more progressive (better performing) organisations.
Average performance is likely to be significantly lower. Nevertheless, there is enough variability here to facilitate some useful analysis, which we will come to in a minute.
We can assume that at the simplest level, performance can be considered as a function of value and cost/efficiency. It is then possible to identify a group of particularly high-performing IT departments, which represents about 15 per cent of the survey sample (figure 2).
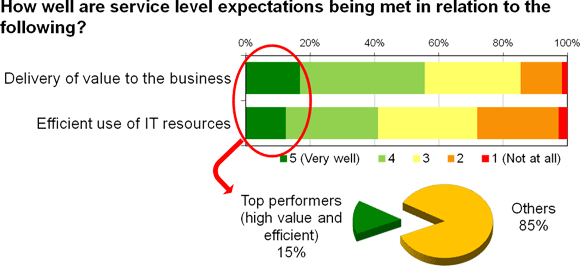
Figure 2
So what is it that these top performers are doing to reach such dizzy heights of success in IT service delivery?
Could do better
When you stand back and analyse cause and effect (as we analysts tend to do quite a bit), you can easily come up with a list of factors that affect IT service delivery in one way or another (figure 3).
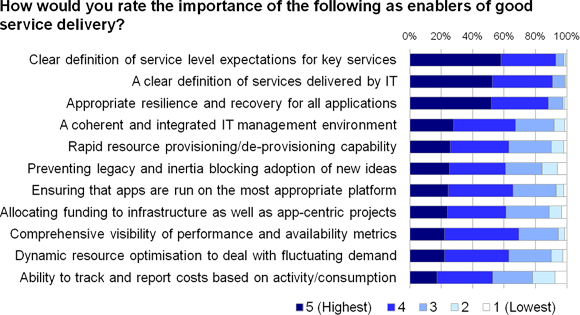
Figure 3
The fact that every item on this list was rated at an importance level of four or five out of five by at least 50 per cent of respondents tells us that most people have a good feel for what they should be doing.
The trouble is, though, that while the top performers are delivering reasonably well, most of the other 85 per cent generally are not (figure 4).
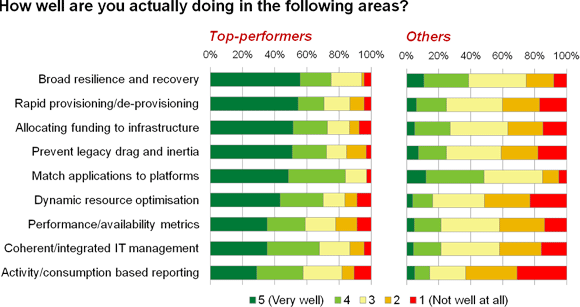
Figure 4
This is reminiscent of comparing report cards at school. For some it might bring back memories of secretly hoping the smug kid who was good in class and on the playing field would some day get his just deserts.
Unless you were that smug kid, of course, in which case you might be tutting and shaking your head while looking over at the losers and wondering how they could be so bad at everything.
Innocent victim
But before we run away with the notion that the majority of IT departments are not doing their jobs properly, it is worth remembering that some of the shortcomings are caused by factors beyond their control.
Take the item at the top of the list, for example: resilience and recovery. Past research studies have told us that lack of awareness on the part of those specifying requirements often means that high availability and disaster recovery are not scoped into the plans and budgets for new systems.
Even if the IT department asks the relevant questions, when funding is short business stakeholders frequently dismiss the issue.
The problem here is that high availability and disaster recovery are akin to insurance: it feels like spending money to get nothing tangible in return.
It is only when the first failure occurs that IT’s advice is taken seriously, but by then there is no budget available to fund high-availability configurations or backup systems. And who gets it in neck? Yep, it’s those incompetents in IT.
Find the funding
Lack of appropriate funding in general is responsible for many of the performance gaps we see. One factor that makes a huge difference to how well IT professionals can do their job is whether they are allowed to invest in infrastructure.
Over the past decade, business stakeholders have increasingly looked for a direct link between money spent and short-term business value created. Budgets have therefore revolved around applications and systems that deliver some visible new capability that business users can touch and feel.
But it is only when users start screaming about performance that funding is cut loose
Securing funding for proactive infrastructure upgrades and future-proofing measures has become more difficult. You might know that the way things are going your network will not keep up with increasing demand unless you invest in more capacity or improved service management capability.
But it is only when users start screaming about performance issues stopping them from doing their jobs that funding is, often begrudgingly, cut loose.
One irony comes through in our research time and time again. Many IT teams are under constant pressure to reduce costs, but at the same time are prevented from improving efficiency by inadequate and disjointed tools that they are not allowed to upgrade or replace.
Reliance on error-prone manual processes that could easily be automated perpetuates high overheads and costs and keeps IT staff from contributing in ways that really matter.
Because of these constraints, the game being played in many IT departments is to hide infrastructure and tools investment in project budgets. Add a little bit here, a little bit there, and hope no one notices.
But this gets you only so far, and it is no coincidence that allocating funding to infrastructure is high on the list of enablers for our top performers. That’s the real way to do it.
It's just business
Whatever the reasons for the capability gaps, you can start to improve things by establishing what really matters to the business. This brings us back to the fundamentals we were discussing at the start.
Despite the fact that the top performers are not perfect across the whole range of service enablers on our list, the overwhelming majority of them still score a four or five out of five against each of the fundamentals (figure 5).
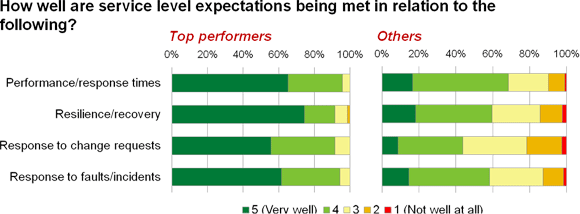
Figure 5
The trick is to know where to focus your efforts and resources. In practice this means having a clear understanding of the business services IT is expected to deliver, and a definition of the service levels associated with the more important ones. The top performers do particularly well in this area (figure 6).
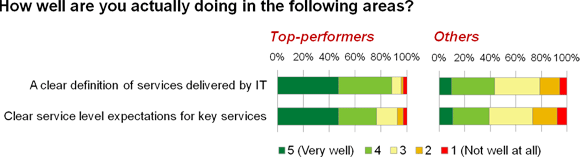
Figure 6
This kind of clarity helps in two main ways. Firstly, it highlights the stuff that it is critical to get right, such as the key services and applications and the associated requirements with regard to performance, availability and so on.
Secondly, it avoids the IT department wasting time and resources on things that are not necessary or helpful.
What not to do
Applications vary immensely in their service-level requirements. The demanding business-critical systems at one end of the spectrum may genuinely need redundant high-end servers, fast resilient storage, high-speed networking and enterprise-class middleware such as cluster-enabled application servers and database management systems, all wrapped in bullet-proof security.
At the other end of the spectrum, however, you might have the application knocked up to help the marketing department do the monthly analysis of partner-related spend, based on extracts from the CRM system.
You might describe this as a convenience app – pretty much as far from business critical as you can get. But would the marketing guys ever admit to that when you are asking them about requirements?
In between, you have every combination of requirements in terms of performance, scalability, resilience, data protection, security, communications and access, and stakeholders, who regardless of real need always ask for the best for their application.
This can easily lead to expensive resources (such as dedicated servers, premium storage and high-end database licences) being used unnecessarily, which means wasted money on both hardware and software.
There’s also the incremental operational burden. How much data do you back up nightly, for example, that hasn’t changed for a week, a month or even a year?
How many servers do you patch routinely that are accessed no more than once a day, once a week or once a year, or have users in single-digit numbers?
Meanwhile, how many genuinely critical systems sit on under-spec’d and under-protected platforms, delivering a poor level of performance that users have given up moaning about because it has been that way for so long?
You can only start to eliminate this waste and exposure by constructing some kind of service catalogue and agreeing the requirements and expectations for at least the key applications and services within the business.
You might then need to pay attention to asset and configuration management if your tooling and processes are not up to the job, but starting with the services layer gives you more chance of drawing a line between spending money on enhanced management capability and things that matter to business people.
And lest we forget, make a point of identifying dormant applications and retire them wherever possible.
Virtues of virtualisation
Freeing up resources in these ways allows you to redirect them more usefully. A priority area here is speeding up change management.
One of the most common complaints from business people, apart from saying that IT costs too much, is that IT takes too long.
Systems-related work, whether it is new functionality or changes to existing applications and services, is often on the critical path to implementing change within the business.
There’s a process dimension here. Whether this can be handled through a spreadsheet, home-grown application or full-blown software package, such as a service desk or project portfolio management system, depends on the scale and complexity of your environment.
Introducing more responsiveness and flexibility at the platform and operations level, though, is also important. Many IT departments are discovering the potential of x86 server virtualisation, which many have adopted as a way of consolidating applications and other workloads onto fewer physical servers.
This has lowered their capital costs and reduced the number of pieces of kit that needed to be managed.
As more and more IT departments gain experience of server virtualisation, they are also appreciating its flexibility and responsiveness.
Being able to provision a new application via a virtual server on an existing piece of kit, for example, avoids the need to procure and configure new servers, which can dramatically speed up the time to deployment.
Being able to migrate workloads easily between servers has then enabled a quicker response to changing demands, for example in an application needing to scale beyond the level originally envisaged.
It is therefore no surprise to see top performers making much more use of x86 server virtualisation than other organisations (figure 7).
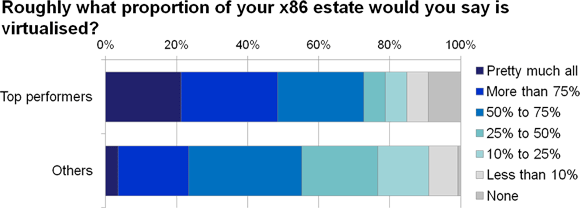
Figure 7
But virtualisation has not been without its issues. A number of our research studies have flagged up virtual server sprawl as a problem for many. Put simply, the ease with which virtual servers can be created means they sometimes proliferate out of control.
Most heavy users of x86 server virtualisation have therefore had to pay attention to beefing up their management environment, and IT vendors have been working hard to deliver the capability required to meet this need.
Meanwhile, some of the key vendors in the virtualisation arena have starting taking flexible x86 based platforms to the next level.
From ‘V’ word to ‘C’ word
The name of the latest game in x86 server computing is private cloud. The basic idea is to pool a bunch of servers and other resources (storage and networking) to create a general-purpose platform upon which a variety of workload types can be run simultaneously.
An important attribute of private cloud is the rapid allocation and de-allocation of resources to and from workloads, enabling a more dynamic approach to management. Private cloud architecture can be used in your own data centre, or set up on dedicated kit in a hosted co-location manner.
Unlike the public cloud, which is often met with a lot of scepticism and cynicism in the IT professional community, private cloud has had a more consistently positive reception.
This is partly because it builds on the familiar concepts of virtualisation management, while at the same time allowing many of the benefits associated with cloud computing to be delivered under the control of the internal IT department.
In our recent survey, we uncovered quite a lot of early adoption activity, particularly among top performers in organisations with large IT infrastructures (figure 8).
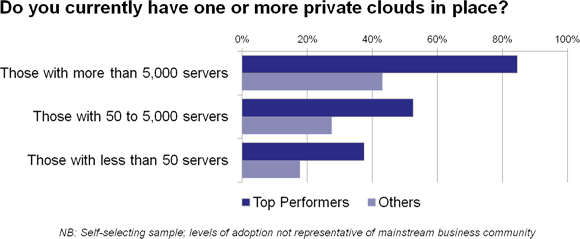
Figure 8
Apart from ease of automation, monitoring and management, the big advantage of private cloud over more traditional virtualisation is that it can support demanding workloads that need to be powered by multiple servers.
Through the concept of elasticity, resources can be allocated to and reclaimed from workloads as demands fluctuate. Together with an ability to achieve higher application availability on a broader basis, this makes private cloud great for service-level management as well as rapid response to new business requirements.
The long-term vision thing
More than ever, platforms, tools and techniques are available that allow a step change in the efficiency and effectiveness of IT service delivery. While we have not been exhaustive here, we have touched on some of the more important principles and developments.
But – and it is a very big but – none of this counts for anything unless business and IT stakeholders jointly recognise the importance of prioritising enhancements to the way IT services are delivered, and provide the resources to invest for the future. Over to you. ®
This is the second article in a two-part series. [The first article is here]. The study upon which this report is based was designed, interpreted and reported by Freeform Dynamics, with data gathered from 570 respondents via an online survey hosted on The Register. The research report "Private Cloud in Context is available for download at The Register's Whitepaper library.
Dale Vile is managing director of Freeform Dynamics, the UK IT analyst firm.
