This article is more than 1 year old
Cray to build huge, grunting 20-petaflop 'Titan' for US gov labs
Still mightier computer colossi to follow
Oak Ridge National Laboratory, one of the big supercomputer centers funded by the US Department of Energy, has tapped Cray to build a monster cluster that will weigh in at 20 petaflops when it is completed next year.
According to a presentation (pdf) by Buddy Bland, project leader for the Oak Ridge Leadership Computing Facility in the Tennessee burg of that same name, cabinets for the Cray machine, nicknamed "Titan", will start rolling into the facility this year. The plan is for the first petaflops of number-crunching power to be installed this year, with the full 20 petaflops of the Titan machine being up and running in 2012.
Jeff Nichols, associate lab director for scientific computing at ORNL, told the Knoxville News Sentinel, that the Titan machine will cost somewhere around $100m. This is about half the price that ORNL paid in June 2006 to commission Cray to upgrade its XT3 systems and then to build the initial XT4 "Jaguar" machine, which weighed in at 263 teraflops.
The current Jaguar box is a mix of XT4 and XT5 cabinets linked by the SeaStar2+ interconnect to create a 2.6 petaflops system with 256,532 Opteron cores and 362 TB of main memory across the nodes.
The future Titan machine will be based on the much better "Gemini" XE interconnect and will stick with the 3D torus topology that the prior XT3, XT4, and XT5 machines used to lash a hierarchy of nodes together.
The interesting twist is that the Titan box will have what ORNL is calling "globally addressable memory," which you might think (as I did) means something close to the shared memory space like Silicon Graphics has implemented with its NUMAlink interconnect for decades. Shared memory systems are a bit easier to program, but that global addressing is distinct from that hyper-NUMA that SGI offers. (IBM has added global addressing to its Power7 chips as well, by the way. IBM has also supported NUMA memory access with its Power4 and later chips for the past decade.) Advanced Micro Devices has supported NUMA memory access from day one with the Opterons, and it is not clear what changes might be in the works for the future "Bulldozer" Opterons to support global addressable memory. The Titan machine will presumably be based on the 16-core "Interlagos" Opterons due later this summer.
Titan will also make use of GPU co-processors to goose the performance of the machine, and given that ORNL inked a deal with graphics chip maker Nvidia back in October 2009 to add GPUs to supers, everyone expects that Nvidia will be the GPU supplier in the Titan box.
It is not clear how many GPUs the Cray design will allow to be crammed into the box, but Cray told El Reg last September that it would be creating GPU blades for the current XT6 systems based on the "Kepler" line of GPU co-processors due from Nvidia this year.
ORNL says that the Titan box will sport larger main memory and a file system that is three times larger and four times faster than the existing clustered disk array created by DataDirect Networks, which is called "Spider" and which runs the Lustre clustered file system controlled by Oracle. That current array has 10.7 PB of capacity and over 240 GB/sec of disk bandwidth.
The Titan machine will run an updated version of Cray's Linux.
ORNL has much bigger plans and has set its sights on breaking the exaflops barrier before the end of the decade:
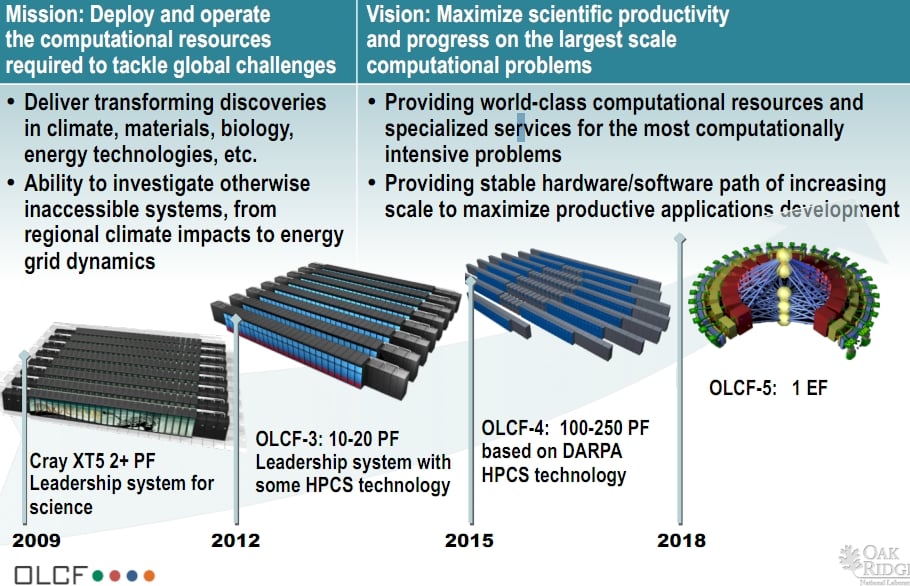
ORNL's "Titan" OLCF-3 system is two steps away from exaflops (click to enlarge)
The OLCF-4 system, which is due in 2015, will scale from 100 to 250 petaflops and will be based on the "Cascade" system design that the US Defense Advanced Research Projects Agency is paying Cray to develop right now.
This machine will use the future "Aries" interconnect and will link nodes and co-processors together through PCI-Express links and will support both AMD Opteron and Intel Xeon processors as compute nodes and very likely a variety of co-processors, including GPUs and FPGAs.
And out in 2018, with the OLCF-5 design, Cray is moving to a new ring structure and hopes to hit an exaflops of raw oomph. ®
