This article is more than 1 year old
InfiniBand to outpace Ethernet's unstoppable force
Run faster or be crushed
Comment Every good idea in networking eventually seems to be borged into the Ethernet protocol. Even so, there's still a place in the market for its main rival in the data center, InfiniBand, which has consistently offered more bandwidth, lower latency, and often lower power consumption and cost-per-port than Ethernet.
But can InfiniBand keep outrunning the tank that is Ethernet? The members of the InfiniBand Trade Association, the consortium that manages the InfiniBand specification, think so.
InfiniBand, which is the result of the merger in 1999 of the Future I/O spec espoused by Compaq, IBM, and Hewlett-Packard and the Next Generation I/O competing spec from Intel, Microsoft, and Sun Microsystems, represents one of those rare moments when key players came together to create a new technology — then kept moving it forward. Sure, InfiniBand was relegated to a role in high-performance computing clusters, lashing nodes together, rather than becoming a universal fabric for server, storage, and peripheral connectivity. Roadmaps don't always pan out.
But since the first 10Gb/sec InfiniBand products hit the market in 2001, it's InfiniBand, more than Ethernet, that has kept pace with the exploding core counts in servers and massive storage arrays to feed them, which demand massive amounts of I/O bandwidth in the switches that link them. Which is why InfiniBand has persisted despite the onslaught of Ethernet, which jumped to Gigabit and then 10 Gigabit speeds while InfiniBand evolved to 40Gb/sec.
Now the race between InfiniBand and Ethernet begins anew. As El Reg previously reported, the IEEE has just ratified the 802.3ba 40Gb/sec and 100Gb/sec Ethernet standards, and network equipment vendors are already monkeying around with non-standard 100Gb/sec devices. At the SC09 supercomputing conference last fall, Mellanox was ganging up three quad data rate (QDR, at 40Gb/sec) InfiniBand pipes to make a twelve-port 120Gb/sec switch. This latter box is interesting, but it is not adhering to the current InfiniBand roadmap:
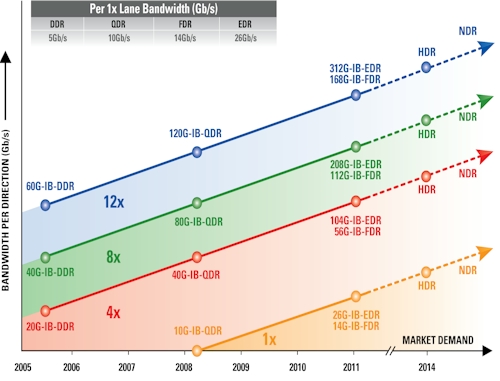
InfiniBand is a multi-lane protocol. Generally speaking, says Brian Sparks, co-chair of the IBTA's marketing working group and the senior director of marketing at Mellanox, the four-lane (4x) products are used to link servers to switches, the eight-lane (8x) products are used for switch uplinks, and the twelve-lane (12x) products are used for switch-to-switch links. The single-lane (1x) products are intended to run the InfiniBand protocol over wide area networks.
As each new generation of InfiniBand comes out, the lanes get faster. The original InfiniBand ran each lane at 2.5Gb/sec, double data rate (DDR) pushed it up to 5Gb/sec, and the current QDR products push it up to 10Gb/sec per lane.
